
 |
Stream Handler - The computer vision application development workbench. Overview. |
The main problems of image processing |
The streams of data in computer vision tasks contain very large amounts of the data that must be processed very quickly.
In practical applications usually presents other types of data, that must be included in the processing chain. That can be audio, text streams, time marks, synch data, etc. During processing all that data must be collected on base some criteria, usually time, to synchronize the processing which results the output streams - with format which can't be predicted for universal cases.
Streams can come from many various sources, including local or remote devices (such as video cameras, GPS, position sensors etc.), local media files, computer networks, and other media devices. These streams come in a variety of formats, from different devices, frequently in proprietary formats.
And at last, usually all that huge amount of information pass through whole processing chain without any visualization, we can't control process of the data processing and we could decide about results of processing only after whole data processing will be done.
Stream Handler is designed to address each of these problems. Its main design goal is to simplify the task of creating computer vision applications on the Windows platform by isolating applications from the complexities of the data processing multithreading, simplifying data transports and synchronization issues and most importantly, the Stream Handler's Developer workbench gives an simple way to control any data on all stages of processing in real time.
The data processing multithreading issue is achieved by implementing of each elementary processing operation in independent module called Gadget. Each Gadget has one processing thread which can be replicated an arbitrary number of times and one or more Connectors. Connectors are intended for data transfer and data queueing between Gadgets. This modular architecture in which Gadgets can be mixed and connected arbitrary - provides support for many different scenarios.
Data is stored in DataFrame containers. Typically, a DataFrame container has a tree structure and can contain related data of different types. The entire life cycle of a DataFrame is automated: creation, transfer between Gadgets and destruction. Gadget can add new DataFrame to existing container and pass it for following processing, or replace container with new one. The simplifying data transport and synchronization issues are attained by data encapsulating in time-stamped data frames. Each data frames can be easily serialized for transport through networks or storing in a file.
Essentially, that Stream Handler system is designed in pure C++ and do not use COM approach, like other similar system - DirectShow by Microsoft. That allows quite simplify the new elements development and including in a system.
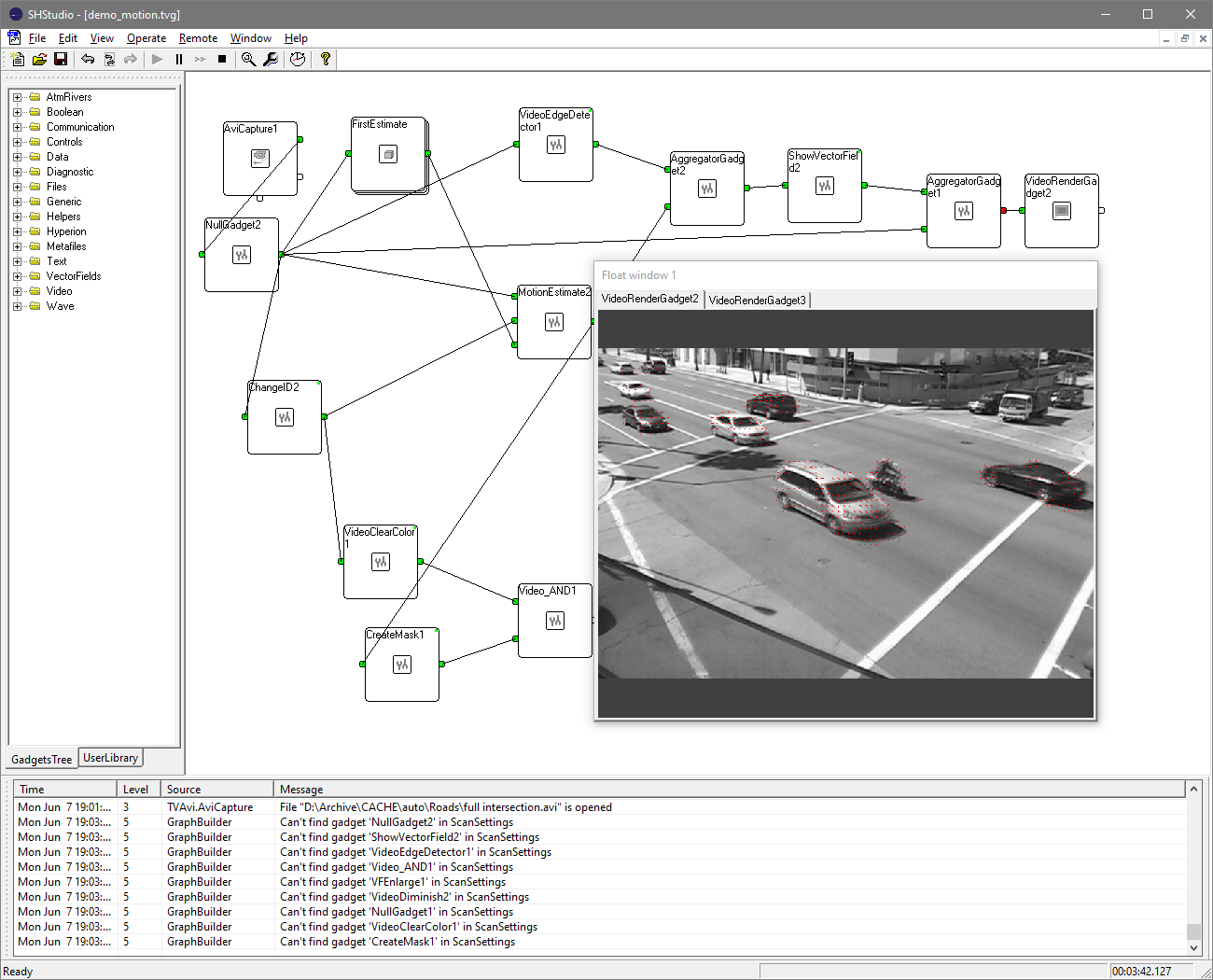
The Stream Handler SDK distributive provides a visual tool SHStudio for creation and testing the processing graphs. It allows interactively build processing graph and estimate any intermediate results of processing. The creation of the processing graph can be made in vivo, i.e., when graph is running and data steams through the graph. It is possible to insert new gadgets, connect them or disconnect, inspect data passed through the graph in any point of the graph.
The resulting graph can be saved in a file and then be linked to host application written on C++ or C#. Any visualization and setup interfaces can be easily integrated in your application interface.
SHStudio tool interface:
Every gadget has a set of default properties that can be changed through the SHStudio interface:
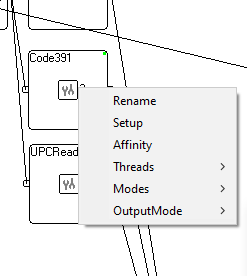
In common gadget has setup property, it's possible to rename it and set its affinity (bind it the specific logic processor). Some gadgets have additional properties such as type of processing and output mode. In addition, some gadgets can be replicated, i.e., run several working threads in them but it looks like a single gadget.
A group of gadgets can be aggregated. Such an aggregated gadget can contain an any size graph of gadgets and is an analogous of function in conventional programing languages. Any of these an aggregated gadget can be saved in the library for future use just like any regular gadgets.
The gadgets have input and output pins. Any output pin can be connected to unrestricted number input pins. And any number of output pins can be connected to one input pins.
The data is transmitted between pins in DataFrames. A DataFrame can contain any number of elementary data packets that are stored in a tree structure. The elementary data packets have a type marker, ID and time of creation. There are 12 predefined types, but there is a possibility to declare any number of custom types.
The gadget development SDK allows create new gadget fo SH engine and gives a possibility to link SH kernel dll to C++ or C# application. There is a set of VS2017 wizards to easy creation new gadgets or new gadget dll. After creation new gadget by this wizard the only what remains to do is to implement gadget's DoProcessing function. It is as simple as writing console application in C++: all the care of the data lifecycle, multithreading and synchronization is taken care of by the SH core. If other options are required, for example setup option, the wizard create commented templates for implementation such a feature.
The interface libraries on managed or native code are suggested in frames of SDK for incorporating whole possibilities of SH into your application on C++ or C#. The suggested possibilities include: loading processing graph, exchange data between application and the graph, linking graph control gadgets interfaces, setup and graph editing tools in the application.
There are detail samples and manual which helps easy start in writing custom gadgets and applications.
This software is the property of intObjects and FileX Ltd. on a parity basis.